Montrez patte blanche : tuez des mutants !
Faites-vous confiance à vos logiciels préférés ? Probablement. Pourquoi leur faites-vous confiance ? L’ont-ils mérité ? La pléthore d’outils que nous utilisons au quotidien nous est souvent imposée par les mêmes personnes qui attendent de notre travail une haute qualité. Pourtant, dans le feu de l’action, rares sont ceux qui questionnent la qualité des ces outils là.
Le test logiciel est plébiscité dans l’industrie pour montrer patte blanche. Compte tenu des contraintes du monde réel (temps, argent), une question se pose : quels tests dois-je écrire ? Ou formulé autrement, dès lors que nous avons la notion de bon test : quand dois-je arrêter d’en écrire ? Pour nous aider à y répondre, nous utilisons souvent la couverture de code par les tests dans l’industrie. Dans cet article, je présente une suggestion de complément à cette mesure, une pratique : le test de mutation.
Dans un premier temps, nous reviendrons sur les concepts évoqués ci-dessus, en nous demandant à quoi ils peuvent nous servir. Dans un second temps, nous nous concentrerons sur l’écosystème Go : d’abord en passant en revue les outils qui automatisent le test de mutation, puis en utilisant ces outils pour savoir si nous avons raison de nous fier à nos logiciels (écrits en Go) préférés.
D’une spécification à la confiance dans son implémentation logicielle
Un programmeur programme pour satisfaire un besoin. L’expression de ce besoin est souvent laconique et informel : il faut le préciser. L’élicitation des exigences doit permettre d’en lever les zones d’ombres, et l’analyse de ces exigences d’aboutir à la spécification d’un logiciel. Cette spécification est la base sur laquelle le programmeur repose pour écrire le code source du logiciel.
Prenons un exemple : la première étape du kata « FizzBuzz ». Nous pouvons la reformuler comme suit :
Écrire une fonction qui prend, en entrée, un entier, et qui retourne « fizz » si l’entier est multiple de trois, « buzz » s’il est multiple de cinq, « fizzbuzz » s’il est multiple à la fois de trois et de cinq, et simplement l’entier dans les autres cas.
Je me suis prêté à l’exercice en programmant une implémentation de cet énoncé en Go, une fonction nommée MyFizzBuzz :
// (module : git.sr.ht/~arjca/fizzbuzz ; fichier : fizzbuzz.go)
package fizzbuzz
import "strconv"
func MyFizzBuzz(n int) string {
if n%15 == 0 {
return "fizzbuzz"
}
if n%3 == 0 {
return "fizz"
}
if n%5 == 0 {
return "buzz"
}
return strconv.Itoa(n)
}
À ce stade, nous pouvons nous demander si l’énoncé est correctement implémenté. Autrement dit : si j’utilise MyFizzBuzz, se comportera-t-elle comme prévu ?
Répondre à ce genre de questions est crucial dans l’industrie. En effet, le dysfonctionnement d’un logiciel peut coûter très cher aux organisations qui les développent, et avoir des conséquences dramatiques pour celles qui les utilisent. Concentrons-nous donc sur ce sujet.
Vérifier que la spéc. est correctement implémentée
Comment s’assurer qu’un logiciel se comporte comme prévu ? Comme dit dans l’introduction, la pratique courante dans l’industrie du numérique est de tester : vérifier que le logiciel se comporte conformément aux attentes dans une situation précise.
Écrivons un test pour MyFizzBuzz. Quand l’entier en entrée égale trois, la consigne dit que MyFizzBuzz devrait produire « fizz ». Ce test est automatisé par le code suivant :
// (fichier : fizzbuzz_test.go)
package fizzbuzz_test
import (
"git.sr.ht/~arjca/fizzbuzz"
"testing"
"github.com/stretchr/testify/assert"
)
func TestMyFizzBuzz_3ShouldReturnFizz(t *testing.T) {
assert.Equal(t, "fizz", fizzbuzz.MyFizzBuzz(3))
}
Exécutons le :
$ go test .
ok git.sr.ht/~arjca/fizzbuzz 0.007s
Le test est réussi. Il y a au moins un cas dans lequel MyFizzBuzz se comporte correctement. Cela signifie-t-il que le logiciel est dépourvu de bogue ? Certes non, comme l’a dit Dijkstra :
tester un programme peut démontrer la présence d’un bogue, jamais son absence.
Pour dissiper tous soupçons sur MyFizzBuzz, il nous resterait bien du travail : 18 446 744 073 709 551 615 tests doivent encore être écrits (car les int occupent 64 bits sur ma machine).
Écrire autant de tests n’est évidemment pas raisonnable ; nous allons devoir en écrire moins, et les bons tests. Mais qu’est-ce qu’un bon test ? Pas simple comme question, et apparemment pas prioritaire car une autre s’impose : quand pouvons nous nous arrêter d’en écrire ? Une réponse naïve pourrait être : « Quand nous aurons suffisamment confiance dans le logiciel ! ». Reste à déterminer les mesures sur lesquelles fonder cette confiance.
Qu’ai-je déjà vérifié ?
Une première piste, largement suivie dans l’industrie, est de mesurer la couverture de code par les tests. Communément, il s’agit du pourcentage de lignes du code source parcourues lors de l’exécution des tests (alternativement, nous pourrions compter les fonctions, les modules, …).
Calculons cette couverture pour MyFizzBuzz :
$ go test . -cover
ok git.sr.ht/~arjca/fizzbuzz 0.002s coverage: 57.1% of statements
Pour l’instant, 57.1% des lignes de MyFizzBuzz sont parcourues en exécutant le test. Est-ce assez ?
Il n’y a pas de réponse consensuelle à cette question. Dans l’industrie, il n’est pas rare de trouver des objectifs pour la couverture de code par les tests. 80% est un nombre récurrent, aussi bien dans les retours d’expérience de collègues que dans ma propre expérience professionnelle. Cela veut quand même dire qu’il y a 20% du code source sans le moindre contrôle. Dans des échanges en ligne, nous pouvons trouver d’autres sons de cloche. Certains disent que 99% ou 100% sont des objectifs souhaitables, tandis que d’autres refusent tout minimum pour cette métrique.
Une raison fréquemment invoquée pour refuser un minimum de couverture à atteindre, ou pour réduire ce minimum, est que cela mène à un surcoût (car cela augmente le nombre de tâches de développement : soit un surcoût financier car il faut plus de programmeurs, soit un surcoût temporel incompatible avec le respect des dates de livraison). À mon étonnement, j’ai rarement vu mentionné en ligne le surcoût lié à un dysfonctionnement non détecté lors du développement, qui justifie la démarche de test.
S’il y a un seuil à atteindre, peu importe lequel dans ce que nous avons mentionné plus haut, MyFizzBuzz n’est pas à la hauteur. Améliorons ce score avec un nouveau test :
// (fichier : fizzbuzz_test.go)
package fizzbuzz_test
import (
"git.sr.ht/~arjca/fizzbuzz"
"testing"
"github.com/stretchr/testify/assert"
)
func TestMyFizzBuzz_3ShouldReturnFizz(t *testing.T) {
assert.Equal(t, "fizz", fizzbuzz.MyFizzBuzz(3))
}
func TestMyFizzBuzz_yolo(t *testing.T) {
for n := 0; n < 500; n++ {
fizzbuzz.MyFizzBuzz(n)
}
}
À présent, recalculons :
$ go test . -cover
ok git.sr.ht/~arjca/fizzbuzz 0.002s coverage: 100.0% of statements
Nous voici à présent à 100% de couverture ! Peu importe l’objectif, il est forcément atteint. Hélas, nous avons un peu triché : le nouveau test ne vérifie pas les valeurs produites par MyFizzBuzz… Qu’avons-nous donc montré ? Tout au plus, qu’il n’y a pas de code mort dans MyFizzBuzz : nous avons pu parcourir toutes les lignes de la fonction. Mais ce n’est pas ça que nous voulions !
En définitive, la couverture de code par les tests n’est pas un indicateur suffisant de la correction d’un logiciel. Il nous faut la compléter.
Mutez les tous !!! La spéc. reconnaîtra les siens !
Voici une autre piste à explorer. Nous avons un plan de test qui valide un code source, certes ; mais que pouvons-nous conclure s’il valide aussi un autre code source ? Assurément, cela soulèverait des doutes quant à sa qualité, nous aurions raison de nous demander ce que ce plan de test valide réellement. Idéalement, comme nous avons pris des décisions pour programmer le logiciel comme ça et pas autrement, le plan de test devrait valider ce code source là et pas un autre.
Précédemment, nous avons écrit un test, TestMyFizzBuzz_3ShouldReturnFizz, en toute bonne foi en reposant sur la consigne. Tentons de le faire échouer en modifiant légèrement MyFizzBuzz :
- if n%3 == 0 {
+ if n%3 != 0 {
return "fizz"
}
Exécutons les tests :
$ go test . -cover
--- FAIL: TestMyFizzBuzz_3ShouldReturnFizz (0.00s)
fizzbuzz_test.go:12:
Error Trace: /home/arjca/Projets/fizzbuzz/fizzbuzz_test.go:12
Error: Not equal:
expected: "fizz"
actual : "3"
Diff:
--- Expected
+++ Actual
@@ -1 +1 @@
-fizz
+3
Test: TestMyFizzBuzz_3ShouldReturnFizz
FAIL
FAIL git.sr.ht/~arjca/fizzbuzz 0.003s
FAIL
Comme prévu, le test échoue. Nous avons bien constaté que TestMyFizzBuzz_3ShouldReturnFizz aboutit à un succès avec MyFizzBuzz mais pas avec une de ses variantes. Nous venons de réaliser un test de mutation :
- Le plan de test valide le code source de
MyFizzBuzz; - Nous altérons ce code source : nous générons un mutant. Une règle permettant de générer un mutant s’appelle un mutateur. Par exemple, un mutateur peut demander la modification d’un
<en un<=, ou bien changertrueenfalse. Notons que les mutateurs peuvent générer des mutants identiques sémantiquement au code source d’origine : c’est un mutant équivalent ; - Nous confrontons le plan de test au mutant. Si au moins un test échoue, bingo : nous avons tué le mutant. Autrement, le mutant survit. Naturellement, nous voulons tuer le plus de mutants que possible.
Expérimentons une seconde mutation :
- if n%5 == 0 {
+ if n%5 != 0 {
return "buzz"
}
Exécutons le plan de test. Nous constatons qu’aucun test n’échoue :
$ go test .
ok git.sr.ht/~arjca/fizzbuzz 0.002s
Le mutant a survécu. Si un mutant survit, alors la ligne contenant la mutation est faiblement testée : il manque peut-être un test (p. ex. si la couverture de code par les tests n’est pas élevée), ou alors les tests existants ne sont pas de bonne facture.
Un plan de test par mutation peut générer un très grand nombre de mutants, et nous pouvons en tirer une mesure : le score de mutation. Il est le ratio du nombre de mutants tués sur le nombre total de mutants non-équivalents. Plus le score de mutation est élevé, plus le plan de test rejette ce qui n’est pas le code source d’origine ; autrement dit, plus il rejette les tests bidons.
Néanmoins, il nous faut évoquer deux difficultés :
- Détecter un mutant équivalent n’est pas trivial ;
- Le nombre de mutants peut être très, très grand, et demander un nombre déraisonnable de manipulations.
Pour surmonter la première difficulté, diverses approches existent : par exemple, pour détecter les mutants équivalents, ou simplement pour ne pas les générer. Une revue de ces approches a été réalisée par Madeyski et coll. en 2017.
Pour surmonter la seconde difficulté, nous pouvons déjà nous demander comment éviter les mutants inutiles : ceux qui sont équivalents à un autre mutant. Afin d’y parvenir, Fernandes et coll. proposent un ensemble de règles pour leur génération. Si cela diminue le nombre de mutants à générer et à essayer de tuer, cela demande encore énormément de calculs : il nous faut les automatiser.
Automatiser le test de mutation en Go
La suite de cet article est consacrée au test de mutation avec le langage Go. Il existe plusieurs outils pour automatiser le test de mutation en Go ; je les passe en revue dans cette section.
Manbearpig
Manbearpig est un outil développé par Daniel Huckstep en 2013. Il va à l’essentiel : l’utilisateur spécifie un paquetage et un mutateur, puis l’outil génère les mutants et les confronte aux tests.
Par exemple avec MyFizzBuzz :
$ manbearpig -import git.sr.ht/~arjca/fizzbuzz -mutation "=="
2024/04/13 18:54:46 mutating in /tmp/manbearpig1715124091
2024/04/13 18:54:46 found 3 occurrence(s) of == in fizzbuzz.go
2024/04/13 18:54:46 mutating == to !=
2024/04/13 18:54:46 mutation 1 broke the tests properly
2024/04/13 18:54:46 mutation 2 broke the tests properly
2024/04/13 18:54:46 mutation 3 failed to break any tests
L’outil indique seulement le nombre de mutants générés ; nous manquons de détails quant à la ligne concernée par chaque mutation, et les tests qui ont tué chaque mutant. Par conséquent, il est difficile d’analyser les résultats et d’en tirer grand chose. Le score de mutation peut être déduit des traces ; cela reste très manuel, d’autant plus qu’il est nécessaire d’utiliser plusieurs fois l’outil pour couvrir toutes les mutations qui nous intéressent.
Mutator
Mutator est un outil développé par Kamil Kisiel en 2013. Lui aussi va à l’essentiel, avec seulement un paquetage à fournir, et éventuellement des mutateurs.
Par exemple avec MyFizzBuzz :
$ mutator git.sr.ht/~arjca/fizzbuzz
using /tmp/mutate4042507686 as a temporary directory
fizzbuzz.go has 3 mutation sites
mutation fizzbuzz.go:7:10 tests failed as expected
mutation fizzbuzz.go:11:9 tests failed as expected
mutation fizzbuzz.go:15:9 did not fail tests
D’une certaine manière, cet outil est complémentaire à Manbearpig : ici, nous savons quelle ligne accueille chaque mutation, mais pas quel mutateur est utilisé… Une seule utilisation est requise pour calculer le score de mutation, mais ce calcul demeure manuel.
Ooze
Contrairement aux projets précédents, qui sont des outils utilisables via une interface en ligne de commande, Ooze est une bibliothèque. Elle est développée principalement par Guilherme Tramontina et continue de recevoir des mises à jour.
Pour l’utiliser, j’ai ajouté un nouveau fichier dans mon module :
//go:build mutation
// (fichier : mutation_test.go)
package fizzbuzz_test
import (
"testing"
"github.com/gtramontina/ooze"
)
func TestMutation(t *testing.T) {
ooze.Release(t)
}
Il ne reste plus qu’à l’exécuter :
$ go test -tags=mutation
┃ Releasing Ooze…
[...]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ • Total: 18 ┃
┃ • Killed: 7 ┃
┃ • Survived: 11 ┃
┠┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┨
┃ ⨯ Score: 0.39 (minimum: 1.00) ┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
--- FAIL: TestMutation (5.02s)
FAIL
exit status 1
FAIL git.sr.ht/~arjca/fizzbuzz 5.021s
Nous avons ici bien plus de détails ! Les lignes que j’ai omises par souci de lisibilité documentent les mutants survivants. Le récapitulatif à la fin contient le score de mutation : 39% pour MyFizzBuzz. Pas fameux !
Notons que la bibliothèque permet d’implémenter de nouveaux mutateurs (appelés virus dans ooze).
Go-mutesting
Go-mutesting est un outil développé par trois personnes de l’entreprise russe Avito.
$ go-mutesting .
[...]
FAIL "/tmp/go-mutesting-619693096/fizzbuzz.go.17" with checksum 25620396c64f05efbecca57ef98b046e
The mutation score is 0.333333 (6 passed, 12 failed, 0 duplicated, 0 skipped, total is 18)
Tout comme ooze, cet outil donne des détails sur les mutants survivants (que j’ai ici omis pour ne pas polluer l’espace !). Il calcule également le score de mutation : 33%. Ce n’est pas le même que celui de ooze car ils n’utilisent pas les mêmes mutateurs, mais cela reste un score médiocre.
Avec cet outil, il est également possible de définir de nouveaux mutateurs en implémentant une interface, mais il faut que cela soit enregistré dans le code source de l’outil ; il faut donc soit y contribuer, soit cloner ce projet.
Gremlins
Gremlins est un outil initié par Davide Petilli et aux nombreux contributeurs.
Il dispose d’options pour limiter le nombre de mutants évalués, et en particulier il se base sur la couverture de code par les tests : si une ligne n’est pas couverte par un test, alors il n’y a pas de raison de générer un mutant pour savoir si elle est correctement testée. Cela peut avoir des effets de bord non désirés. Par exemple, l’outil intégré à Go pour générer la couverture de code n’indique pas si les case ... des switch sont couverts ou non, ils ne sont juste pas suivis ; par conséquent, une mutation qui devrait être réalisée dans ces lignes ne sera pas générée par gremlins.
Pour MyFizzBuzz, cela donne :
$ gremlins unleash
Starting...
Gathering coverage... done in 344.804964ms
KILLED CONDITIONALS_NEGATION at fizzbuzz.go:11:9
LIVED ARITHMETIC_BASE at fizzbuzz.go:15:6
LIVED CONDITIONALS_NEGATION at fizzbuzz.go:15:9
LIVED ARITHMETIC_BASE at fizzbuzz.go:7:6
KILLED ARITHMETIC_BASE at fizzbuzz.go:11:6
KILLED CONDITIONALS_NEGATION at fizzbuzz.go:7:10
Mutation testing completed in 322 milliseconds 805 microseconds
Killed: 3, Lived: 3, Not covered: 0
Timed out: 0, Not viable: 0, Skipped: 0
Test efficacy: 50.00%
Mutator coverage: 100.00%
Le score de mutation, appelé ici « efficacité des tests », égale 50% ; encore un autre score !
L’exemple de MyFizzBuzz est un peu court pour mettre en lumière les fonctionnalités de gremlins. Nous pouvons noter :
- Utilisation de plusieurs cœurs CPU pour générer et évaluer plusieurs mutants à la fois ;
- Possibilité de générer des mutants uniquement pour les lignes modifiées entre deux contributions sur Git, ce qui permet d’accélérer grandement l’exécution ;
- Génération d’un rapport en JSON pour des traitements a posteriori ;
- Possibilité de déclarer un objectif pour le score de mutation. Le code de sortie d’une exécution est un code d’erreur si l’objectif n’est pas atteint (utile par exemple dans une chaîne CI/CD) ;
- Les tests peuvent passer en
TIMEOUTs’ils prennent trop de temps à être exécutés ; Cela permet d’accélérer l’exécution du test de mutation mais dégrade la précision du test de mutation. Le temps-limite est calculé avec le temps d’exécution du plan de test sur le code source original, et un facteur multiplicatif.
Résumé
Nous avons passé en revue plusieurs outils pour automatiser le test de mutation en Go. D’un côté, Manbearpig et Mutator sont d’anciens projets qui ne sont pas tenus à jour ; de l’autre, Ooze, Go-mutesting, et Gremlins sont des outils aux fonctionnalités similaires.
Je propose quelques constats :
- le score de mutation calculés par chaque outil est différent. C’est dû aux mutateurs utilisés : tous les outils n’évaluent pas les mêmes mutants. Le score de mutation n’est donc pas comme la couverture de code par les tests : sa valeur dépend beaucoup de l’outil de mesure. Cependant, je ne pense pas qu’un plan de test donnant un score médiocre avec un outil puisse donner un score excellent avec un autre. Il y a juste des outils un peu plus optimistes que d’autres ;
- Gremlins et Go-mutesting génèrent des rapports utilisables par ailleurs, par exemple pour afficher les lignes de code faiblement testées dans un IDE. Cependant, ces rapports suivent des conventions différentes ;
- à part Ooze, il est nécessaire de contribuer au développement de l’outil, ou d’en créer une version alternative, pour ajouter un mutateur ;
- aucun de ces outils ne permet une utilisation incrémentale, c’est-à-dire que chaque exécution de ces outils entraîne l’analyse intégrale du code source. Certes, Gremlins a une option
diffpour restreindre l’analyse à une portion du code, mais cela ne permet pas de recalculer le score de mutation pour l’ensemble du projet ; - Gremlins est le seul outil de cette revue qui fait des compromis entre la précision du score de mutation et le temps d’exécution.
À présent munis d’un moyen d’automatiser le test de mutation, nous pouvons mener de nouvelles investigations.
Des projets populaires à l’épreuve de la mutation
Pour finir cet article, nous pouvons enfin revenir à la question initiale : avons-nous raison de faire confiance à nos logiciels préférés ?
Nous allons y répondre sous le prismes des notions présentées plus haut, et en nous cantonnant aux projets écrits en Go.
Objectif
L’objectif est de vérifier si le plan de test des projets (logiciels, bibliothèques) populaires en Go sont de bonne qualité.
Les projets que nous allons considérer ici sont les logiciels et les bibliothèques écrits en Go (et non, p. ex., les tutoriels) et hébergés sur GitHub. Pour simplifier la notion de popularité d’un projet, nous allons considérer leur nombre d’étoiles sur GitHub. Nous nous intéressons donc aux projets ayant le plus d’étoiles. Comme présenté plus haut, nous allons aussi réduire la qualité d’un plan de test à sa couverture de code et son score de mutation. Nous allons devoir définir ce qui est une valeur élevée pour ces deux mesures. Pour la suite, je choisis arbitrairement que :
- une couverture de code par les tests élevée est d’au moins 80% (ce qui laisse tout de même 20% du code source libre de tout contrôle) ;
- un score de mutation élevé est d’au moins 80% (ce qui signifie tout de même que le plan de test « laisse passer » 20% des variantes générées à partir du code source).
L’hypothèse que nous allons vérifier est la suivante : un projet populaire a mérité sa popularité en démontrant sa qualité à travers un plan de test de bonne qualité. Nous allons raffiner cette hypothèse en deux sous-hypothèses :
- un projet populaire a une haute couverture de code par les tests ;
- un projet populaire a un haut score de mutation.
Si un projet a une haute couverture de code par les tests et un score de mutation médiocre, alors un grand nombre de ses tests sont bidons. S’il a une faible couverture et un grand score de mutation, alors la petite portion du code testée peut être jugée fiable. Si ces deux métriques sont faibles, nous ne pouvons rien tirer du plan de test. Dans ces trois cas, la popularité du projet doit être expliquée par autre chose que sa qualité (p. ex. la publicité, la mode).
Échantillonnage des projets
Pour commencer, nous devons lister les projets populaires à analyser. Prenons les 300 projets de la catégorie Go sur GitHub qui ont le plus d’étoiles. Pour lister leurs URL, utilisons l’outil en ligne de commande de GitHub :
gh search repos --topic go --sort stars --limit 300 --json url | jq -r ".[].url"
Cela aboutit… à une liste de 300 liens. Tous ne nous intéressent pas. En effet :
- certains des dépôts contiennent des exemples et des tutoriels, avec certes du code Go mais dont on n’attend pas qu’il soit testé pour que les gens veuillent bien l’utiliser ;
- d’autres sont des agrégations de sources diverses, des livres ou bien des logiciels écrits dans un autre langage que Go : bref, il n’y a pas de code Go à tester.
Une première passe nous permet d’en éliminer 34. Il reste donc 266 dépôts à analyser.
Mesures réalisées
Pour investiguer les projets, j’ai utilisé quelques outils :
- nombre d’étoiles sur GitHub :
gh(l’outil en ligne de commande de GitHub) ; - couverture de code par les tests : l’outillage inclus dans la distribution de Go ;
- score de mutation : Gremlins, car même s’il aboutit à des scores de mutation un peu plus élevés que les autres, ses fonctionnalités m’ont permis de réaliser l’analyse de tous les projets dans un temps « raisonnable ».
J’ai réalisé les calculs en plusieurs étapes.
D’abord, j’ai réalisé une première passe des projets pour en extraire les informations les plus rapides à produire, notamment :
- leur nombre d’étoiles sur GitHub ;
- leur nombre de lignes de code ;
- la durée d’exécution du plan de test ;
- la couverture de code par les tests. Cette étape est importante car, si exécuter le plan de test est supposé être rapide, nous allons devoir l’exécuter de très nombreuses fois pour évaluer le score de mutation : avec des moyens matériels limités pour réaliser l’étude, nous devons faire des choix. Par exemple, exécuter le plan de test du projet aws-sdk-go prend près d’une minute et demi sur ma machine ; or, le projet compte presque six millions de lignes : le plan de test risque d’être exécuté des millions de fois, ce qui peut être déraisonnablement long.
Ensuite, pour chaque projet retenu, j’ai exécuté les tests de mutation.
Résultats
De nombreux jours de calcul plus tard, voici venue l’heure des résultats ! (ici, les résultats compilés au format CSV)
Premières remarques :
- le fichier contient 256 entrées, soit 10 de moins qu’attendu. En effet, j’ai compté une entrée par module Go dans les dépôts, et certains n’en avaient aucun. Néanmoins, certains autres en avaient plusieurs (voir la colonne
Folder) ; - les tests ont échoué dans 129 modules, soit un peu plus de la moitié des modules analysés. Dans la plupart des cas, c’est lié à des dépendances attendues sur la machine qui exécute les tests : par exemple, les tests de Minikube sont dépendants de libvirt. Étant donné le nombre de projets à analyser, je n’ai pas étudié chacun dont les tests sont en échec. J’ai décidé de simplement les mettre de côté ;
- j’ai mis huit modules de côté car, étant donné leur taille et la durée d’exécution de leurs tests, cela aurait été trop long de calculer leur score de mutation.
Finalement, j’ai calculé la couverture de code par les tests de 125 modules, et le score de mutation de 117 d’entre eux.
D’abord, jetons un œil sur un premier graphique avec des données « démographiques » sur nos projets. Les projets sélectionnés sont assez variés, autant dans leur nombre de lignes de code que dans leur nombre d’étoiles sur GitHub. La variance est immense. Nous n’observons pas de corrélation entre le nombre de lignes de code et la popularité des projets, ni entre le nombre de tests et leur popularité. Cela n’est pas très étonnant. En revanche, il n’apparaît pas non plus de corrélation entre le nombre de tests et le nombre de lignes de code, ce qui est curieux : à voir s’il s’agit de surqualité dans certains petits projets avec beaucoup de tests, ou de sous-qualité dans les autres.
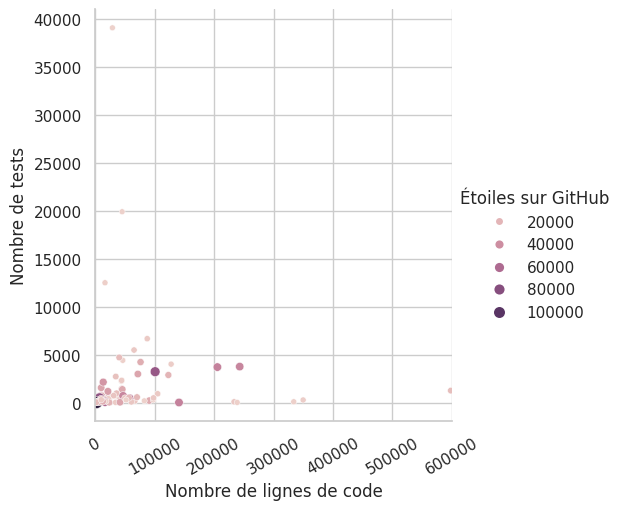 Nombre de tests par ligne de code des modules analysés
Nombre de tests par ligne de code des modules analysés
Ensuite, intéressons-nous à la couverture de code par les tests. Le graphique ci-dessous montre plusieurs choses :
- nous identifions deux pics : un premier entre 50% et 60% de couverture de code par les tests, et un autre un peu moins grand autour de 20% ;
- les plus grands projets en nombre de lignes de code (LOC > 100000) ont pour la quasi-totalité une couverture de code par les tests inférieure à 60% ;
- seuls 22 modules ont 80% de couverture ou plus, soit environ 18% des modules analysés.
Cela permet de trancher pour la première hypothèse : non, les projets écrits en Go les plus populaires n’ont pas une bonne couverture de code par les tests.
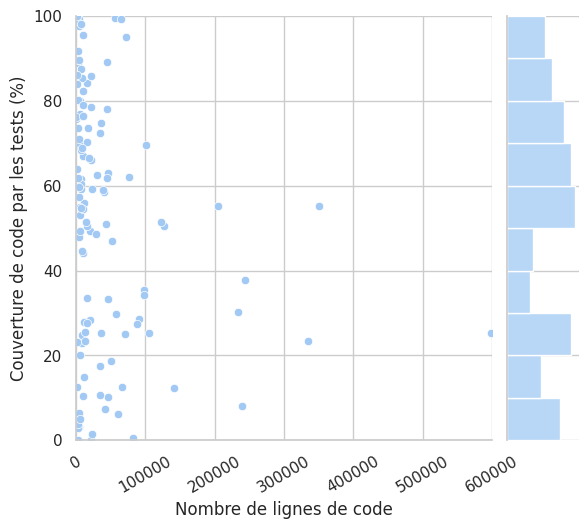 Couverture de code par les tests en fonction du nombre de lignes des modules analysés
Couverture de code par les tests en fonction du nombre de lignes des modules analysés
Enfin, voyons les résultats des tests de mutation. À nouveau, il est difficile d’établir la moindre corrélation à partir de cette figure. Cependant, il est évident que si de nombreux modules n’ont pas une grande couverture de code par le test, le score de mutation est, lui, plutôt élevé en général. Remarquons toutefois que les projets avec une bonne couverture ont aussi systématiquement un score de mutation élevé (> 60%), ce qui n’est pas le cas de certains projets avec une moindre couverture.
Pour revenir à notre hypothèse, nous comptons 49 modules avec un score de mutation supérieur à 80%, soit presque 42% des projets analysés. Valider notre hypothèse dans ces conditions serait exagéré. Notons tout de même la grande concentration des projets autour de ce niveau, 80% : 66% des modules ont un score de mutation supérieur à 70%, et plus de 13% des modules ont un score supérieur à 90%.
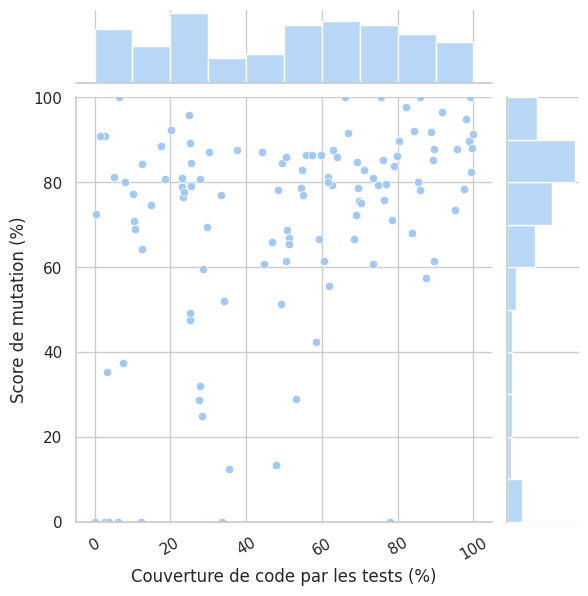 Score de mutation en fonction de la couverture de code par les tests des modules analysés
Score de mutation en fonction de la couverture de code par les tests des modules analysés
Résumé et rétrospective sur l’utilisation du test de mutation
En évaluant la qualité des plans de tests des projets écrits en Go les plus populaires, nous avons conclu qu’avoir un bon plan de test n’est pas un prérequis à la popularité. La plupart de ces projets ont une couverture en deçà des exigences communes de l’industrie.
En plus de cet aperçu de l’écosystème Go, cette investigation a mis en lumière des difficultés vis-à-vis du test de mutation :
- ce type de test est gourmand autant en calcul, en mémoire vive et en stockage sur disque dur. Par conséquent, d’importants moyens sont requis pour le mettre en œuvre sur de grands projets ;
- le temps d’exécution des tests de mutation est parfois très grand, et complètement tributaire de la taille du projet et de la rapidité d’exécution du plan de test. À titre d’exemple, le test de mutation pour le projet Minio a duré près de 2 jours sur ma machine ;
- un score de mutation indique que au plus un certain pourcentage des tests ne valide pas uniquement le code source du logiciel. La précision « au plus » est due aux potentiels mutants équivalents générés dans le processus ; difficile de savoir combien il y en a à chaque fois : cela demanderait une étude de chaque mutant survivant ;
- l’outillage pour l’écosystème Go n’est pas encore idéal. D’après moi, il manque certaines fonctionnalités de confort et d’autres purement pratiques pour pouvoir être démocratisé dans l’industrie.
Les fonctionnalités que j’aimerais voir dans ces outils dans le futur sont les suivantes :
- Reprendre un test de mutation interrompu sans exécuter à nouveau les mutants déjà évalués (p. ex. pour pouvoir lancer les tests de mutation sur une machine préemptible sur Google Compute Engine) ;
- Restreindre les tests exécutés à ceux du paquetage contenant le code muté (afin de gagner du temps à l’exécution du test de mutation et à l’analyse des mutants survivants) ;
- Suivre la progression d’un test de mutation (p. ex. avec une barre de progression qui indique le nombre de mutants déjà évalués, sur le nombre de mutants total) ;
- Utiliser le test de mutation au fur et à mesure des évolutions, sans avoir à effectuer à nouveau l’intégralité du processus à chaque fois.
Conclusion
Dans ce (finalement) long article, nous avons rappelé les bases du test logiciel, de pourquoi nous le faisons et d’une question que les programmeurs devraient se poser : quels tests sont nécessaires et suffisants ? Pas de réponse claire à cette question, seulement des indices. L’un d’entre eux est la couverture de code par les tests, une mesure commune dans l’industrie pour évaluer la qualité d’un plan de test. Cependant, cette mesure n’est pas fiable seule, c’est pourquoi nous pourrions l’accompagner du score de mutation. Plusieurs outils existent dans l’écosystème Go pour automatiser le calcul du score de mutation. Nous nous en sommes servi sur des projets très populaires à titre d’exemple. Cette expérience nous a montré que, si ces projets sont très utilisés, ce n’est sans doute pas parce qu’ils ont fait la preuve de leur qualité dans leur plan de test. Une hypothèse pour expliquer ces manques : pas assez de moyens ; cependant, les importants scores de mutation que nous avons calculés devraient conforter l’idée que le travail réalisé est de bonne facture. En tant qu’informaticien, il est important que nous questionnions les outils de notre quotidien, et ne pas nous laisser influencer par la publicité. Plutôt que d’être de simples consommateurs, à nous de contribuer à ces outils pour les rendre plus sûrs et accroître leur qualité, sinon leurs fonctionnalités.
En guise d’ouverture, je souhaitais souligner que la couverture de code par les tests et le score de mutation sont deux mesures pour évaluer un certain aspect de la qualité d’un plan de test. Ils ne suffisent pas, puisqu’ils sont complètement indépendants de la spécification. À l’avenir, nous pourrions réfléchir à une nouvelle mesure qui établi à quelle point la spécification d’un logiciel est couverte par un plan de test : la couverture de spécification par les tests. En attendant, le développement dirigé par les tests (TDD) est une pratique à envisager car, d’une part, elle devrait aboutir à une couverture de code par les tests proche de 100% sans falsification et, d’autre part, c’est la spécification qui dirige la création des cas de test. À ce sujet, je vous recommande de visionner la présentation que Ian Cooper a donné en 2017 à la conférence DevTernity.
J’ai initialement publié cet article sur le blog de Stack Labs sur Dev.to. Je remercie mes collègues pour leur relecture.